SECTION 03 · DATASET
§3
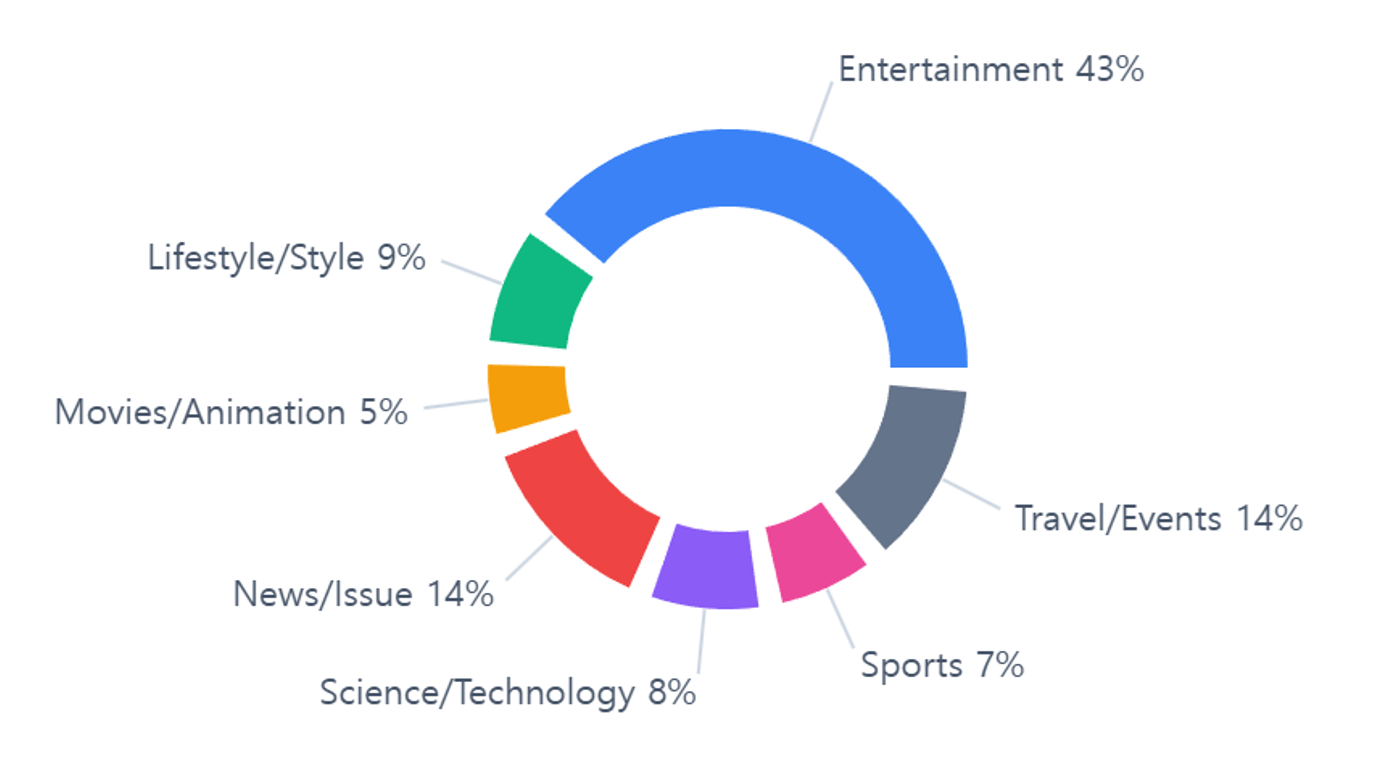
≈10k samples across 7 categories and ~80 channels.
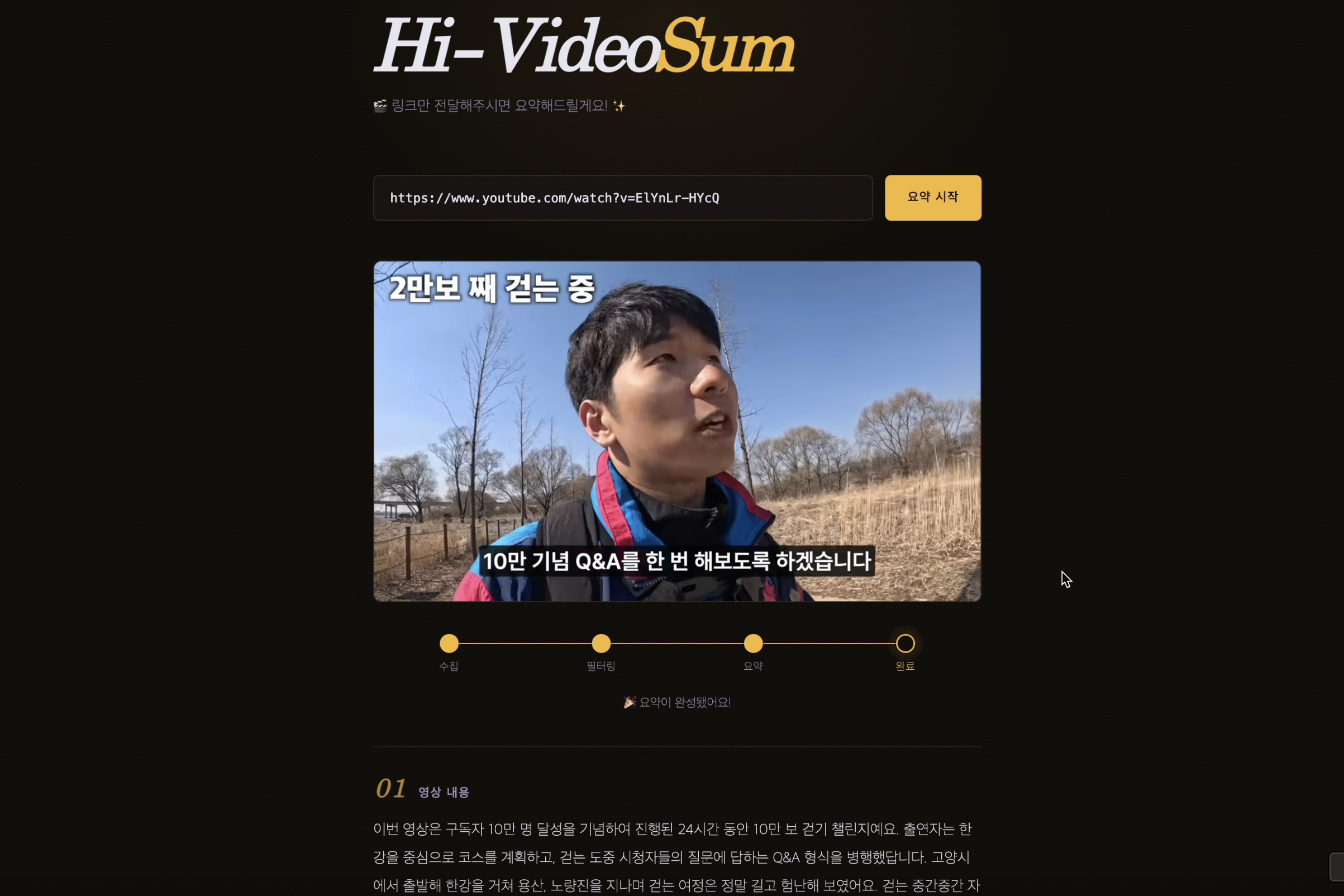
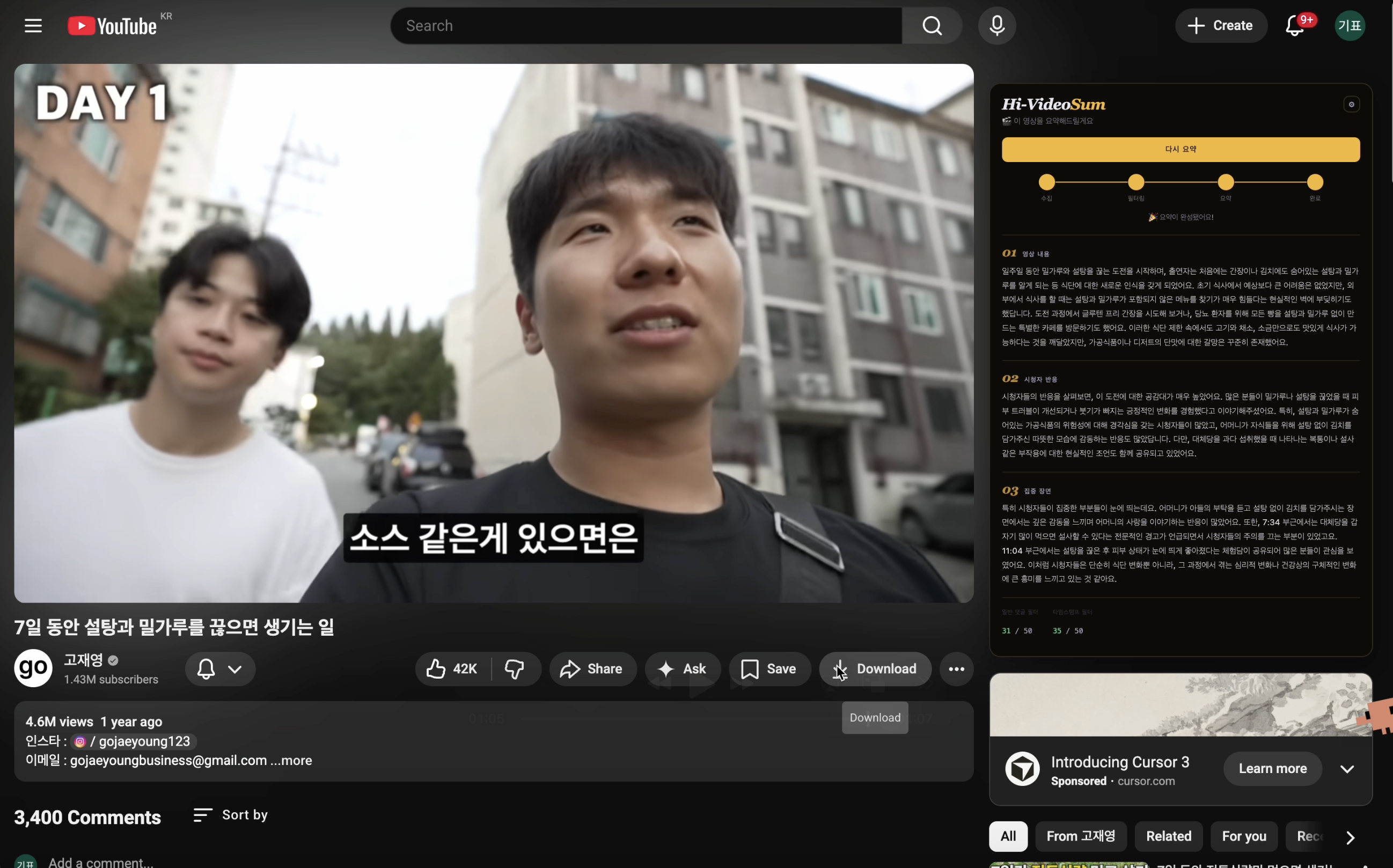
Sourced entirely from Korean YouTube. Each video becomes one JSONL row carrying transcript, general comments, and timestamped comments.
Released on HuggingFace Hub as kim586w/hivideosum_training_dataset.
80ch
curated Korean YouTube channels
Channels
7/16
top-level / sub-categories
Categories
≈10k
three-paragraph training pairs
Samples
5–30m
video length window
Length